
Aunque Twine pudo ser un buscador encargado de indexar semánticamente toda la Web, arrancó con un objetivo más sencillo: hacerse cargo de aquellas partes que la gente considera valiosas. Con la adquisición de Twine.com por la Empresa EVRI, el 11 de marzo del 2011, esta interesante aplicación fue retirada de la red. En su lugar surgió un “motor de descubrimiento de contenido móvil” al que se denominó EVRI. http://www.evri.com.
EVRI es un buscador que se especializa en la devolución de resultados de las últimas noticias, temas seguidos regularmente, nuevos temas y recomendaciones de amigos. La plataforma central de la tecnología de EVRI se basa en el procesamiento del lenguaje natural y búsquedas semánticas, para proporcionar canales de contenido agregado en millones de temas.
Wolfram Alpha, desarrollado por la compañía Wolfram Research, es otra importante aplicación Web 3.0 que surgió el 15 mayo de 2009. Este buscador, al que se le llamó “Motor de Conocimiento Computacional”, es un servicio en línea que responde directamente las preguntas del usuario, en lugar de proporcionar una lista de los documentos o páginas Web que podrían contener la respuesta, como lo hace Google.
Wolfram Alpha se basa en la tecnología “Question Answering” o “QA”, para la recuperación de la información. QA es un método que procesa el Lenguaje Natural de una forma más compleja que otros sistemas de recuperación de documentos, razón por la que se le observa como un paso por delante de la tecnología de los buscadores tradicionales para Internet. Asimismo se basa en uno de los anteriores programas creados por Wolfram Research: “Mathematica”, que incluye el procesamiento de álgebra, cálculo numérico y simbólico, visualizaciones y capacidades estadísticas. http://www.wolframalpha.com.
Diferencias entre los buscadores semánticos y los tradicionales
A fin de ilustrar las diferencias entre las tecnologías de los buscadores tradicionales y los semánticos, se presenta el siguiente ejemplo: suponga que usted desea localizar en Internet los datos del presidente de México. A fin de trabajar de la misma manera con los buscadores, la búsqueda se realizará en inglés. La cadena a buscar será: “President of Mexico”.
Google, uno de los buscadores más conocidos y utilizados, es capaz de arrojar millones de resultados por cada palabra de búsqueda. Esta sobreabundancia de resultados responde al hecho de que las webs del momento son sintácticas, esto es, se sirven de las palabras, los términos, para ser localizadas por los buscadores.
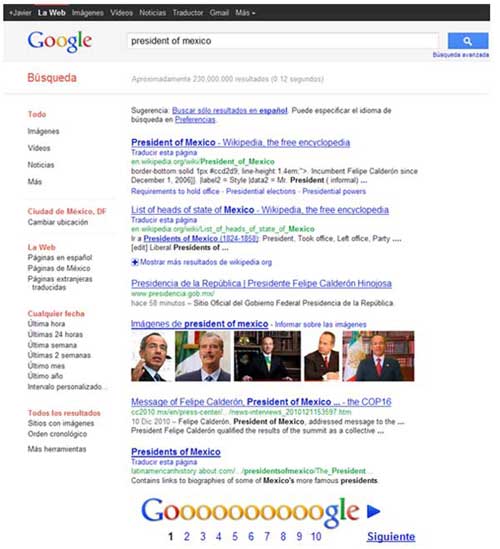
En la figura 2 note que Google entregó una lista con todas las páginas que encontró con la información solicitada (230,000,000 de resultados en 0.12 segundos), sin duda muchas en un tiempo muy corto. No obstante, si analizamos los resultados obtenidos, nos damos cuenta que tendremos que revisar cada una de las ligas para extraer los datos que requerimos.
La misma búsqueda, pero ahora realizada con Wolfram Alpha, nos arroja resultados que son sin duda más apegados a las necesidades y deseos del usuario final
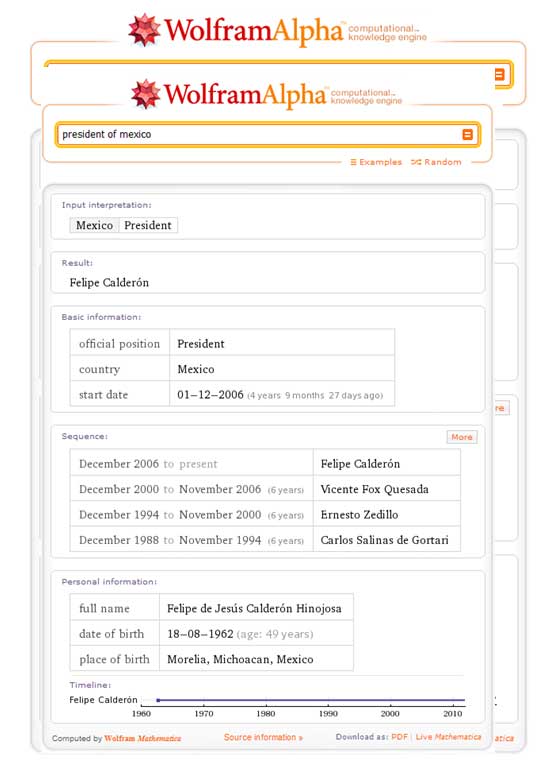
Esta es la promesa de los buscadores semánticos o Web 3.0: ajustar las búsquedas de información a las necesidades de los usuarios.
La misma búsqueda, pero ahora realizada con el buscador “EVRI”, sin duda arroja resultados actualizados e interesantes, pero con el enfoque comercial para el cual fue concebido: “mostar sólo las últimas novedades del presidente de México”
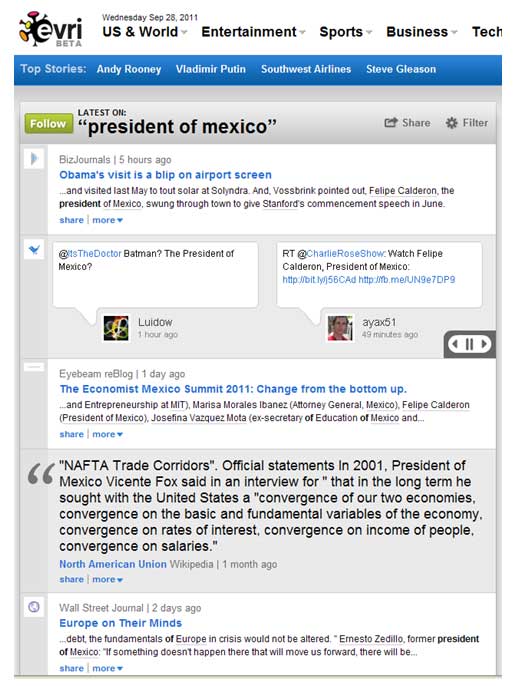
Como puede apreciarse, hay una diferencia significativa entre los resultados arrojados por cada uno de los buscadores.
Vale la pena mencionar también que Google ha estado trabajando en el desarrollo de un producto de búsqueda semántica. De hecho el pasado 3 de junio de 2009 fue lanzado Google Squared. Este buscador permitía extraer datos estructurados de toda la Web y presentaba sus resultados en un formato parecido al de una hoja de cálculo. Google Squared actualmente no está disponible en la red, pues se cerró después de una serie de pruebas a fin de mejorar las búsquedas. También en Julio de 2010, Google adquirió a la empresa Metaweb. Esta empresa es una compañía líder en el tema de Web semántica. Son quienes están detrás de Freebase, una inmensa base de datos, de la cual Google ya venía usando servicios para su sitio de noticias.
Otro buscador Web de importancia, que está tratando de introducir el uso de la tecnología semántica, es Bing de Microsoft, que fue puesto en línea el 3 de junio de 2009. Bing está basado en la tecnología semántica desarrollada por la empresa Powerset y que Microsoft compró en 2008 para el enriquecimiento de sus búsquedas.
Por otra parte, en lo que se refiere al tema de los buscadores semánticos, el pasado 2 de junio de 2011 Google, Yahoo y Bing, anunciaron la creación de un proyecto al que llamaron schema.org para acercar la Web semántica a cualquier página basada en la tecnología Rich Snippets (“Fragmentos Ricos”) de Google, que surgió en el 2009.
Entre las características y mejoras que ofrece schema.org, destacan las siguientes:
- Posibilidad de etiquetar muchos tipos de información, como por ejemplo: restaurantes, productos, eventos, sonidos, recetas, etcétera.
- Unificar la estructura de los datos. Hasta ahora podíamos trabajar con RDFa, microdatos o microformatos. A partir de ahora todo se centrará en microdatos; eso sí, el resto seguirán teniendo soporte, al menos por el momento.
No hay comentarios:
Publicar un comentario