La Web semántica es una de las tecnologías de información y comunicación que posiblemente agradará más a los internautas, por las bondades que promete, entre ellas:
Organizar la gran cantidad de Información suelta, redundante y de calidad dudosa, existente en la Web actual;
Reducir los costos y los tiempos que invertimos en localizar información útil en la Web, porque actualmente debemos realizar el análisis semántico de la información;
Establecer las reglas para integrar información con diferentes formatos, y
Resolver los problemas de interoperabilidad entre diversos dispositivos y plataformas con los que accedemos a la Web.
Así, en este artículo se tratará de dar una visión del actual grado de desarrollo de esta tecnología.
El término “Web 3.0” apareció por primera vez en 2006, en un artículo del diseñador de páginas Web estadounidense Jeffrey Zeldman, crítico de la Web 2.0 y fundador de la empresa Happy-Cog para el desarrollo de páginas Web. Este término, utilizado por el mercado para promocionar las mejoras con respecto a la Web 2.0, básicamente describe la evolución del uso y la interacción con la Web a través de la incorporación de las siguientes tendencias tecnológicas:
La transformación de la Web en una base de datos distribuida: a través del lenguaje de marcas extensible XML (“eXtensible Markup Language”), la estructura para la descripción de recursos, en base a metadatos, RDF (“Resource Description Framework”), y diversos microformatos que permiten agregar significado semántico a los contenidos.
La introducción de la tecnología de Web semántica: emplea búsquedas en lenguaje natural y la minería de datos. Clasifica la información de manera más eficiente, a fin de devolver resultados más precisos a las solicitudes de búsqueda de los usuarios.
Hacer los contenidos Web accesibles desde múltiples dispositivos:comprende el diseño de las interfaces para que puedan ser accedidas desde múltiples dispositivos, tales como teléfonos inteligentes, televisores digitales, iPad´s, PDA´s, etc.
El uso de las tecnologías de inteligencia artificial: por medio de programas especializados (Agentes Inteligentes), para comprender mejor lo que la gente solicita.
La Web geoespacial: que combine la información geográfica disponible de los usuarios, con la información que predomina en la Web, generando contextos que permiten realizar búsquedas u ofrecer servicios en base a la localización.
Uso de la tecnología para 3D:que transforme la Web actual en espacios tridimensionales inmersivos, donde los usuarios puedan sumergirse e interactuar.
Los orígenes de la “Web semántica”, por su parte, se remontan al año 2001, cuando el científico británico Tim Berners Lee (Inventor de la World Wide Web) y el investigador en inteligencia artificial James Hendler (del Departamento de Ciencias de la Computación de la Universidad de Maryland), presentaron un artículo en la revista Nature abordando por primera vez la posibilidad de generar este tipo de Web. En el artículo explican que la Web debería estar diseñada no sólo como espacio de información accesible para los seres humanos, sino también como espacio donde pudieran acceder las computadoras. El objetivo del acceso por parte de las computadoras sería ayudar a los seres humanos a buscar y conseguir la información que necesitan, con la mayor rapidez y garantía de éxito posibles.
Ante la imposibilidad de compartir la información entre computadoras con la Web actual, estos autores propusieron adaptar los documentos de Internet con una nueva tecnología, que permitiera procesar los datos también por computadora, es decir, encontrar la información en forma rápida y eficaz, basándose en el significado y no en los términos.
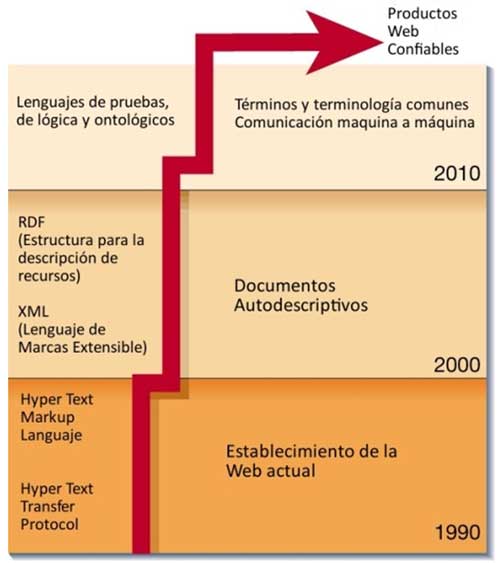
La Web semántica define un nuevo modelo de Web (figura 1), con una capacidad muy superior a la que conocemos actualmente, regido por los principios de las búsquedas semánticas y la inteligencia artificial.
Bajo este nuevo modelo, las páginas Web adquieren un significado propio, el cual tiene como objetivo primordial facilitar las búsquedas de información, ajustándose más a satisfacer los intereses de los usuarios que las realizan.
La información que contienen actualmente las páginas de Internet, carece de una estructura preestablecida, lo que impide que las máquinas sean incapaces de procesar la información, como si se tratase de un ser humano, es decir, comprendiendo su significado
La Web semántica define un nuevo modelo de Web (figura 1), con una capacidad muy superior a la que conocemos actualmente, regido por los principios de las búsquedas semánticas y la inteligencia artificial.
Bajo este nuevo modelo, las páginas Web adquieren un significado propio, el cual tiene como objetivo primordial facilitar las búsquedas de información, ajustándose más a satisfacer los intereses de los usuarios que las realizan.
La información que contienen actualmente las páginas de Internet, carece de una estructura preestablecida, lo que impide que las máquinas sean incapaces de procesar la información, como si se tratase de un ser humano, es decir, comprendiendo su significado
La Web semántica surgió con el objetivo de mejorar el lado malo de Internet: “La sobreinformación”. Tener acceso a tanta información, mucha de ella sin la calidad ni el rigor necesario, hace que el usuario, a menudo, se vea saturado de información y colmado de dudas ante lo que está leyendo.
La Web semántica está especialmente diseñada para dotar de significado a su contenido, de tal manera que cuando el buscador trata de localizarlo, no se fija en las palabras que contiene, sino precisamente en el significado, en lo que el usuario de verdad está buscando.
El mecanismo con que funciona la Web semántica se desarrolla a través de ontologías (esquemas conceptuales definidos para el intercambio de información), para añadir significado semántico a la Web, y taxonomías (reglas), para definir objetos y las relaciones que se pueden establecer entre ellos.
La Web semántica, pese a su escaso desarrollo actual, tiene un potencial ilimitadoque permitirá, en poco tiempo, acceder a la información de Internet como nunca.
Ventajas de la Web semántica
Incorpora contenido semántico a las páginas que se suben a Internet. Esto permite una mejor organización de la información, asegurando búsquedas más precisas por significado y no por contenido textual.
Permite a las computadoras la gestión de conocimiento, hasta el momento reservada a las personas (hace uso de inteligencia artificial).
Desventajas de la Web semántica
Es costoso y laborioso adaptar los documentos de Internet, para poder ser procesados de forma semántica (a esto hay que sumar los problemas del idioma).
Es necesario unificar los estándares semánticos y proveer relaciones de equivalencia entre conceptos. Por ejemplo, en el caso del código postal, se debe establecer que CP es igual a ZC “zip code” en el caso del inglés.
El esfuerzo de dotar de significado a las páginas Web vale la pena, ya que producirá una World Wide Web mucho más asequible y entendible, con búsquedas de información más precisas.
Es lo mismo la Web 3.0 que la Web Semántica
Como ya se explicó anteriormente, el término Web 3.0 ha sido utilizado para describir el camino evolutivo de la red e incluye a la tecnología de la Web Semántica. Asimismo, las investigaciones académicas actuales están dirigidas a desarrollar programas que puedan razonar, basados en descripciones lógicas y agentes inteligentes. La Web semántica, por su parte, facilita las búsquedas de información al dotar de significado a los contenidos, lo cual hace que estos conceptos se relacionen ampliamente.
Avances y tendencias de la Web 3.0 o Web semántica
A partir de 2007 comenzaron a surgir varias aplicaciones merecedoras de esta categoría, esencialmente buscadores. Uno de los primeros servicios de Web semántica presentados fue Twine, desarrollado por Radar Networks.

 El servicio de RSS permite difundir información actualizada a usuarios que se han suscrito a una o más fuentes de contenidos. Es un formato desarrollado para compartir contenidos Web en sitios que se actualizan con frecuencia. Los sitios Web que brindan el servicio de RSS, tienen un botón anaranjado (figura 5), el cual permite suscribirse a ellos. Una vez realizado este proceso, bastará con un simple navegador para consultar las novedades del sitio Web solicitado, sin tener que entrar a éste.
El servicio de RSS permite difundir información actualizada a usuarios que se han suscrito a una o más fuentes de contenidos. Es un formato desarrollado para compartir contenidos Web en sitios que se actualizan con frecuencia. Los sitios Web que brindan el servicio de RSS, tienen un botón anaranjado (figura 5), el cual permite suscribirse a ellos. Una vez realizado este proceso, bastará con un simple navegador para consultar las novedades del sitio Web solicitado, sin tener que entrar a éste. Inform. Es un sitio Web que permite ver noticias como piezas interconectadas de un rompecabezas más grande y lo hace de forma automatizada. Inform recoge las noticias de los medios de comunicación en línea y las compañías de información, y se encarga de interconectar y relacionar los temas empleando la tecnología de la Web Semántica. Esto le permite mostrar un panorama más completo alrededor de las noticias (http://inform.com).
Inform. Es un sitio Web que permite ver noticias como piezas interconectadas de un rompecabezas más grande y lo hace de forma automatizada. Inform recoge las noticias de los medios de comunicación en línea y las compañías de información, y se encarga de interconectar y relacionar los temas empleando la tecnología de la Web Semántica. Esto le permite mostrar un panorama más completo alrededor de las noticias (http://inform.com).